One advantage of still (STILL) taking courses toward my Phd is that I can leverage our group projects to explore research questions outside of my core area. This one got a little “meta” – we looked for the factors that are key to students creating groups for successful course projects!
The following is a blog post that we created for our final project in Social Web in HCI, taught by Geoff Kaufman and Hiro Shirado. My teammates are Ruiqi Hu and Endong Zhu.
In current society, collaboration is a vital component of daily life. People collaborate for diverse personal purposes such as romantic dating, pursuing shared interests, addressing community issues, and solving technical problems. This has led to the rise of dozens of computational systems for “social matching” (Terveen & McDonald, 2005). The rise of team-oriented productivity structures in academia and industry has similarly motivated work to create tools for professional social matching (Olsson et al., 2020). While socio-technical research has led to useful solutions for instructors matching up students in group projects – such as CATME (https://info.catme.org/) and Pair Research (http://pairresearch.io/) – we seek to create a computational tool for students who want to self-organize their project groups.
To help us better envision what such a tool might need for its data inputs, we undertook an exploratory research project in Spring 2020 for the Social Web course in the Human-Computer Interaction Institute at Carnegie Mellon University. First, we undertook a literature search through Google Scholar and our existing reference libraries, and we interviewed subject matter experts and gathered feedback from classmates on what competitor tools exist and what other published research was relevant. From this process, we identified several key variables such as team size, fraction of newcomers and incumbents, team skills, and personality traits, from which to create a statistical model of which input variables mattered most for the desired outcomes of excellent grades and group-work satisfaction.
Then, we designed a pilot survey to help us explore these variables with a real-world dataset. We crafted a codebook of survey items corresponding to these variables, from which we then designed and wrote an online questionnaire in Google Forms. We then recruited survey respondents from among our class and personal networks, and we cleaned and prepared the resulting data for statistical analysis using multilinear regression. Finally, we produced charts and graphs to visualize the most important inputs for determining our respondents’ stated grade and satisfaction outcomes.
- Link to survey responses (redacted): https://drive.google.com/open?id=1Ailpx1AdVDOhYF11fZDDuVvBdgAkVaiq
- Code for Parameter Filtering and Data Cleaning: https://github.com/Rachel-Hu/Survey-Analysis
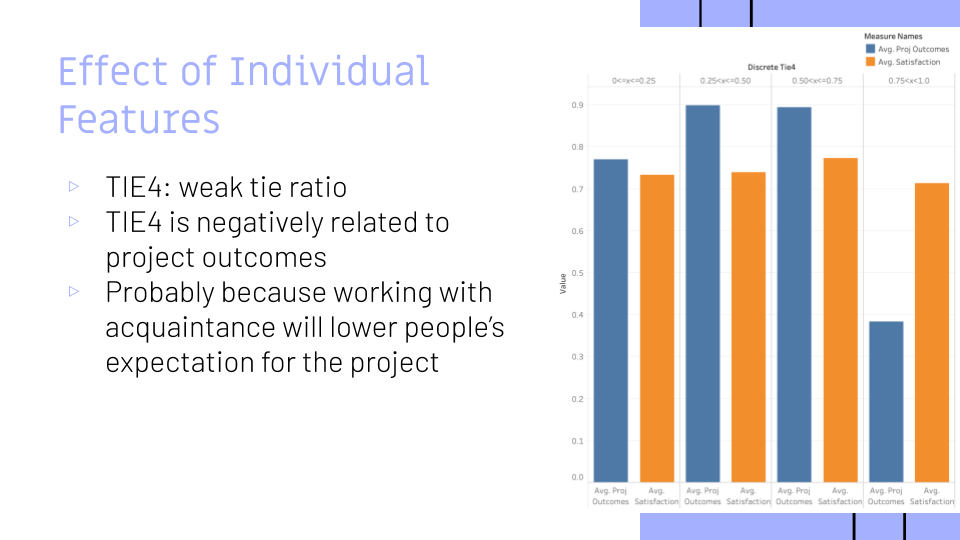
Our results showed, first, that the more “weak ties” or acquaintances that were reported in the group, the lower were the project outcomes. We theorize that this is because working with acquaintances will lower people’s expectations for the project – students may just want to “hang out” with their school friends instead of focusing on the quality of their projects.
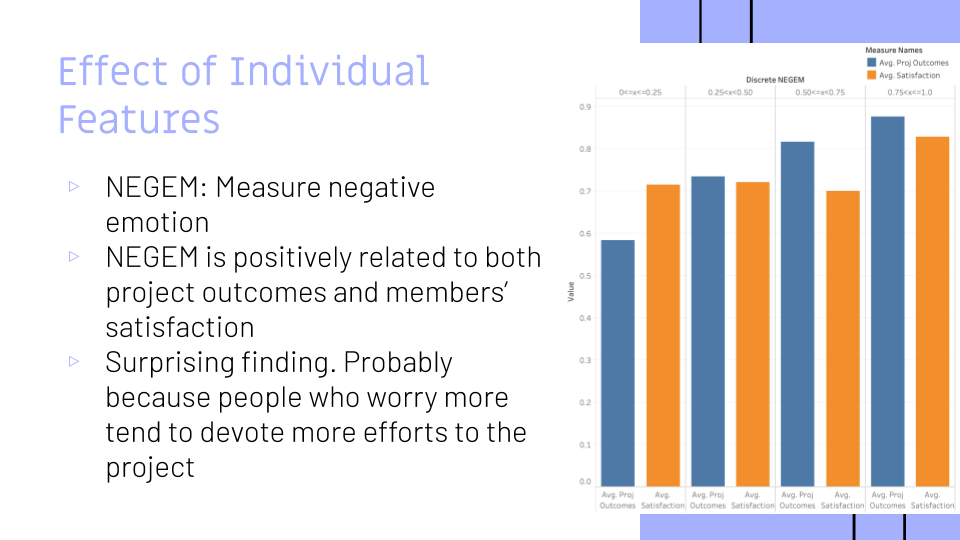
Second, our results show that the personality trait of “negative emotionality,” such as a tendency to anxiety, is positively associated with both project outcomes AND satisfaction. This finding is surprising to us, because we assumed that this trait would have negative effects on outcomes due to creating psychological obstacles or group friction. However, it may be that students who worry more tend to care more and devote more efforts to the project.
This work has validated our initial hunch that using a psychometric and skills-profiling tool may help students to self-assemble a group for their course projects that is more likely to lead to excellent grades and high satisfaction. We see the need in the future to collect a larger survey sample, with a monetary incentive for participation rather than “social capital” among the convenience sample, in order to test whether we can replicate the results.